Basic SBI Model Training¶
In this tutorial, we will walk through the process of training a simulation-based inference (SBI) model using the synference package. We will assume we already have a library of simulations and corresponding parameters.
First let’s consider the training process more generally. The main steps involved in training an SBI model are:
Prepare the Simulation Data: Gather a set of simulations and their corresponding parameters.
Choose a Model Architecture: Select an appropriate neural network architecture for the SBI model.
Define the Training Procedure: Set up the training loop, loss function, and optimization algorithm.
Train the Model: Run the training process and monitor performance.
Evaluate the Model: Assess the trained model’s performance on a validation set.
Now let’s look at how to implement these steps using synference.
[1]:
from synference import SBI_Fitter, test_data_dir
/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
From the output of the library generation tutorials, we should have a HDF5 file called test_model_library.hdf5 in our ‘libraries/’ directory. If you don’t have this file, please refer to the Library Generation tutorial.
We can directly use this file to instantiate a SBI_Fitter instance, which is the class which handles training and evaluating SBI models in synference.
[2]:
fitter = SBI_Fitter.init_from_hdf5(
model_name="test", hdf5_path=f"{test_data_dir}/example_model_library.hdf5"
)
Feature and Parameter Arrays¶
Now this fitter has loaded the generated observations and parameters from the HDF5 file. Note that the data is not yet normalized or set up with the correct features for training. We will handle that in the next steps.
We can see the names of the observations.
[3]:
print(fitter.raw_observation_names)
['JWST/NIRCam.F070W' 'JWST/NIRCam.F090W' 'JWST/NIRCam.F115W'
'JWST/NIRCam.F150W' 'JWST/NIRCam.F200W' 'JWST/NIRCam.F277W'
'JWST/NIRCam.F356W' 'JWST/NIRCam.F444W']
The names of the features:
[4]:
print(fitter.parameter_names)
['redshift' 'log_mass' 'tau_v' 'tau' 'peak_age' 'log10metallicity']
and any associated parameters units:
[5]:
print(fitter.parameter_units)
['dimensionless' 'log10_Msun' 'mag' 'dimensionless' 'Myr' 'log10(Zmet)']
The actual array itself is stored in the parameter_array attribute, which we will just print the first 10 entries of here:
[6]:
print(fitter.parameter_array[:10])
[[ 2.05416274e+00 1.04035606e+01 1.22474718e+00 9.36861515e-01
1.69158648e+03 -3.13879132e+00]
[ 2.00016856e+00 1.04899187e+01 1.28473628e+00 1.60899329e+00
3.02503141e+03 -3.87390995e+00]
[ 2.18753195e+00 1.15228844e+01 2.18956232e+00 1.20334947e+00
1.86831172e+03 -3.46571136e+00]
[ 2.11274648e+00 9.81967258e+00 5.74459910e-01 8.06611896e-01
2.01560364e+03 -1.89818966e+00]
[ 2.44652700e+00 9.17687321e+00 1.38670945e+00 1.77724314e+00
3.07231417e+02 -2.88550878e+00]
[ 6.84367716e-01 1.14148254e+01 2.61994505e+00 3.89508367e-01
3.59630292e+03 -1.86997616e+00]
[ 1.49105906e-01 1.00042429e+01 1.95352912e+00 1.27394879e+00
1.13156527e+04 -2.40571117e+00]
[ 1.71895242e+00 1.17945662e+01 1.94888246e+00 2.07960412e-01
1.57720040e+03 -3.86293936e+00]
[ 2.84610391e+00 9.41966534e+00 2.85131145e+00 8.91395509e-01
1.19775692e+03 -3.77944398e+00]
[ 2.45635724e+00 1.03770952e+01 1.80910027e+00 2.73230791e-01
2.36855774e+03 -1.71073520e+00]]
And a similar logic for the observations:
[7]:
print(fitter.raw_observation_grid[:, :10])
[[1.55361035e+02 6.62787615e+01 2.93631144e+02 6.01755184e+01
6.08683670e+00 2.52897265e+03 6.31139334e+03 5.55954909e+02
3.01451722e-01 7.46139935e-02]
[2.40530441e+02 1.13258320e+02 5.88940061e+02 7.87135295e+01
9.31069105e+00 6.79137932e+03 1.07562514e+04 1.35413814e+03
7.49976727e-01 5.30070034e-01]
[5.07742016e+02 2.91263414e+02 1.41441540e+03 1.44744857e+02
1.48766062e+01 1.40988387e+04 1.63680472e+04 5.82525117e+03
1.77367012e+00 5.52317547e+00]
[1.06025886e+03 5.80749330e+02 3.79225364e+03 3.03962040e+02
3.73309422e+01 2.65854161e+04 2.33425604e+04 1.08011228e+04
5.90461870e+00 3.40313785e+01]
[1.49439723e+03 8.83105895e+02 6.47315587e+03 4.27806729e+02
5.66841099e+01 4.68630971e+04 3.13794258e+04 1.76892096e+04
1.37485025e+01 1.01136398e+02]
[1.90476605e+03 1.16731581e+03 9.31606212e+03 6.26340520e+02
8.70344677e+01 8.13157865e+04 2.26920392e+04 2.70938604e+04
2.74803669e+01 2.37788360e+02]
[2.36584297e+03 1.41584377e+03 1.28469681e+04 8.12406290e+02
1.16919381e+02 7.99288041e+04 1.74361191e+04 3.40880141e+04
3.78438853e+01 3.99970276e+02]
[2.70394000e+03 1.58965237e+03 1.54602400e+04 9.96181433e+02
1.33611502e+02 5.93842217e+04 1.33736683e+04 4.01845570e+04
5.17631635e+01 5.66103013e+02]]
The first step is to turn this raw library of photometric observations into a set of features that can be used for training. This is done with the fitter.create_feature_array method.
This method handles the following tasks:
Normalizing the observations (e.g., converting magnitudes to fluxes, normalizing by a reference band, etc.)
Creating features from the observations (e.g., colors, ratios, etc.)
Removing photometric bands in the library from the feature array that are not present in the observations.
Handling missing data (e.g., setting features to NaN if any of the required bands are missing)
Adding additional features (e.g., redshift) from the parameter array to the feature array.
Adding realistic noise to the features based on a provided noise model (see the Noise Models tutorial for more details).
Adding photometric uncertainties to the feature array.
The default configuration of this method doesn’t do all of these however. By default, all photometric bands are kept, no additional features are added, and no noise is added. The default normalization is to convert the raw array of photometry to AB magnitudes only.
We call the method below and we can see it prints information about the features it creates.
[8]:
fitter.create_feature_array();
2026-06-24 09:49:36,631 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:36,632 | synference | INFO | Features: 8 features over 100 samples
2026-06-24 09:49:36,633 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:36,635 | synference | INFO | Feature: Min - Max
2026-06-24 09:49:36,636 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:36,636 | synference | INFO | JWST/NIRCam.F070W: 7.131974 - 42.758 AB
2026-06-24 09:49:36,637 | synference | INFO | JWST/NIRCam.F090W: 7.108530 - 39.933 AB
2026-06-24 09:49:36,638 | synference | INFO | JWST/NIRCam.F115W: 7.012560 - 38.354 AB
2026-06-24 09:49:36,638 | synference | INFO | JWST/NIRCam.F150W: 6.969396 - 36.997 AB
2026-06-24 09:49:36,639 | synference | INFO | JWST/NIRCam.F200W: 7.133157 - 35.470 AB
2026-06-24 09:49:36,639 | synference | INFO | JWST/NIRCam.F277W: 7.670149 - 33.243 AB
2026-06-24 09:49:36,640 | synference | INFO | JWST/NIRCam.F356W: 8.072730 - 32.490 AB
2026-06-24 09:49:36,641 | synference | INFO | JWST/NIRCam.F444W: 8.353975 - 31.965 AB
2026-06-24 09:49:36,641 | synference | INFO | ---------------------------------------------
We will proceed with the default configuration for now. More advanced configurations will be covered in later tutorials. Using different normalizations/units or adding additional features can have a significant impact on the performance of the trained SBI model.
Before we do any fitting, we can inspect the feature and parameter arrays to see the distribution of the data.
Firstly we can look at the feature array, and see the distribution of the photometry given our model and feature array configuration. The below figure shows a histogram of each feature in the feature array.
[9]:
fitter.plot_histogram_feature_array(bins=20);
2026-06-24 09:49:37,437 | synference | INFO | saving /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots//feature_histogram.png
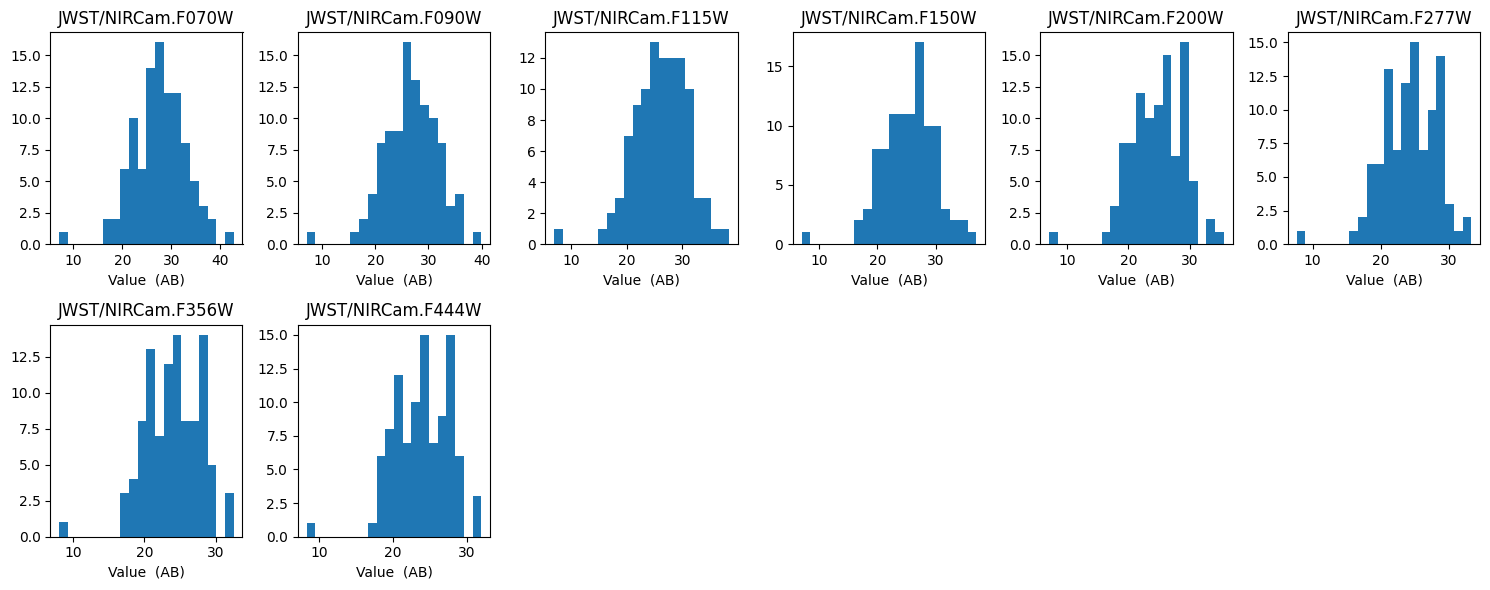
Secondly we can look at the parameter array, and see the distribution of the parameters given our model and parameter configuration. The below figure shows a histogram of each parameter in the parameter array. We can see that the parameters are uniformly distributed, as expected from our library generation configuration.
[10]:
fitter.plot_histogram_parameter_array();
2026-06-24 09:49:39,423 | synference | INFO | saving /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots//param_histogram.png

Training an SBI Model¶
SBI model training is handled with the fitter.train_single_sbi method. This method handles the following tasks:
Creating a prior from the parameter array.
Setting up the neural density estimator (NDE) for the SBI model.
Training the SBI model.
Saving the trained model to disk.
Plotting diagnostics of the trained model.
We will cover the various options for different SBI configurations in later tutorials. For now, we will proceed with the default configuration.
synference is built on top of the LtU-ILI package, which utilizes sbi and lampe for the underlying SBI functionality. The default NDE is a Masked Autoregressive Flow (MAF) from the sbi package. The default prior proposal is a uniform prior over the range of the parameters in the parameter array.
The primary arguments to the fitter.train_single_sbi method are:
train_test_fraction: The fraction of the data to use for training. The rest is used for validation. The default is 0.8.validation_fraction: The fraction of the training data to use for validation during training. The default is 0.2.backend: The backend to use for training. Eithersbiorlampe. The default issbi.hidden_features: The number of hidden features in the NDE. The default is 50.num_components/transforms: The number of components or transforms in the NDE. The default is 4.training_batch_size: The batch size for training. The default is 64.stop_after_epochs: The number of epochs with no improvement to stop training. The default is 15.
There are other methods to turn on or off plotting, model saving, validation, etc. See the docstring for more details.
Now we will run the training, and quite a lot of things will be printed. We are setting name_append to ‘test_1’ so that the trained model is saved with a unique name. If left as the default a timestamp will be used.
[11]:
posterior_model, stats = fitter.run_single_sbi(
name_append="test_1", random_seed=42, hidden_features=256, num_components=64
)
2026-06-24 09:49:40,537 | synference | INFO | Splitting dataset with 100 samples into trainingand testing sets with 0.80 train fraction.
2026-06-24 09:49:40,538 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:40,539 | synference | INFO | Prior ranges:
2026-06-24 09:49:40,541 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:40,541 | synference | INFO | redshift: 0.00 - 4.98 [dimensionless]
2026-06-24 09:49:40,542 | synference | INFO | log_mass: 8.01 - 11.99 [log10_Msun]
2026-06-24 09:49:40,542 | synference | INFO | tau_v: 0.01 - 3.00 [mag]
2026-06-24 09:49:40,543 | synference | INFO | tau: 0.11 - 1.98 [dimensionless]
2026-06-24 09:49:40,543 | synference | INFO | peak_age: 9.03 - 11315.65 [Myr]
2026-06-24 09:49:40,543 | synference | INFO | log10metallicity: -3.98 - -1.41 [log10(Zmet)]
2026-06-24 09:49:40,544 | synference | INFO | ---------------------------------------------
2026-06-24 09:49:40,545 | synference | INFO | Processing prior...
2026-06-24 09:49:40,549 | synference | INFO | Creating mdn network with NPE engine and sbi backend.
2026-06-24 09:49:40,550 | synference | INFO | hidden_features: 256
2026-06-24 09:49:40,550 | synference | INFO | num_components: 64
2026-06-24 09:49:40,551 | synference | INFO | Training on cpu.
INFO:root:MODEL INFERENCE CLASS: NPE
INFO:root:Training model 1 / 1.
Training neural network. Epochs trained: 93
INFO:root:It took 3.780519485473633 seconds to train models.
INFO:root:Saving model to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test
Neural network successfully converged after 98 epochs.2026-06-24 09:49:44,349 | synference | INFO | Time to train model(s): 0:00:03.812459
2026-06-24 09:49:44,358 | synference | INFO | Saved model parameters to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/test_test_1_params.pkl.
2026-06-24 09:49:44,583 | synference | INFO | [ 5.59471250e-01 1.16237526e+01 2.68136740e-01 1.74207807e+00
9.19759094e+02 -3.81416941e+00]
1412it [00:00, 163795.59it/s]
INFO:root:Saving single posterior plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/test_18_plot_single_posterior.jpg...
2026-06-24 09:49:57,514 | synference | INFO | shapes: X:(20, 8), y:(20, 6)
100%|██████████| 20/20 [00:00<00:00, 286.21it/s]
INFO:root:Saving posterior samples to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/posterior_samples.npy...
INFO:root:Saving coverage plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/plot_coverage.jpg...
INFO:root:Saving ranks histogram to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/ranks_histogram.jpg...
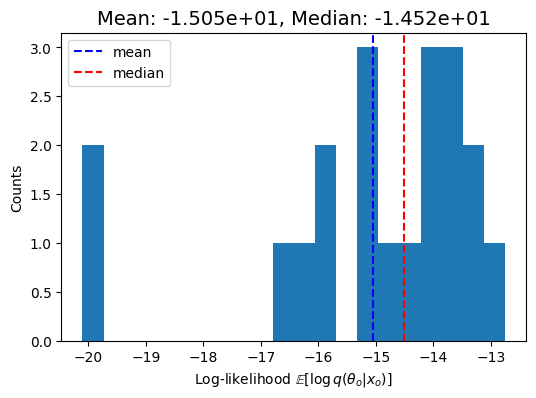
INFO:root:Mean logprob: -1.5050e+01Median logprob: -1.4515e+01
INFO:root:Saving true logprobs to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/true_logprobs.npy...
INFO:root:Saving true logprobs plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_1/plot_true_logprobs.jpg...
INFO:matplotlib.mathtext:Substituting symbol E from STIXNonUnicode
100%|██████████| 100/100 [00:00<00:00, 590.48it/s]
2026-06-24 09:49:59,442 | synference | INFO | Evaluating model...
2026-06-24 09:49:59,444 | synference | WARNING | Transposing samples to match shape (num_objects, num_samples, num_parameters).
100%|██████████| 200/200 [00:00<00:00, 605.38it/s]
Log prob: 100%|██████████| 20/20 [00:00<00:00, 97.03it/s]
2026-06-24 09:49:59,992 | synference | INFO | ============================================================
2026-06-24 09:49:59,993 | synference | INFO | MODEL PERFORMANCE METRICS
2026-06-24 09:49:59,994 | synference | INFO | ============================================================
2026-06-24 09:49:59,994 | synference | INFO | Full Model Metrics:
2026-06-24 09:49:59,995 | synference | INFO | ----------------------------------------
2026-06-24 09:49:59,995 | synference | INFO | TARP..................... 0.052500
2026-06-24 09:49:59,996 | synference | INFO | LOG DPIT MAX............. 0.556575
2026-06-24 09:49:59,997 | synference | INFO | MEAN LOG PROB............ -14.447606
2026-06-24 09:49:59,997 | synference | INFO | Parameter-Specific Metrics:
2026-06-24 09:49:59,998 | synference | INFO | ----------------------------------------
2026-06-24 09:49:59,998 | synference | INFO | Metric redshift log_mass tau_v tau peak_age log10metallicity
2026-06-24 09:49:59,999 | synference | INFO | --------------------------------------------------------------------------------------
2026-06-24 09:49:59,999 | synference | INFO | MSE 1.536651 0.814142 0.605088 0.333565 2951121.419264 0.636731
2026-06-24 09:50:00,000 | synference | INFO | RMSE 1.239617 0.902298 0.777874 0.577551 1717.882830 0.797955
2026-06-24 09:50:00,001 | synference | INFO | MEAN AE 0.983035 0.761332 0.662154 0.495030 1544.325925 0.683114
2026-06-24 09:50:00,001 | synference | INFO | MEDIAN AE 0.761149 0.671130 0.715940 0.505187 1539.468822 0.665392
2026-06-24 09:50:00,002 | synference | INFO | R SQUARED 0.999960 0.999977 0.999984 0.999991 -0.292303 0.999984
2026-06-24 09:50:00,002 | synference | INFO | RMSE NORM 0.001930 0.001405 0.001211 0.000899 2.674235 0.001242
2026-06-24 09:50:00,003 | synference | INFO | MEAN AE NORM 0.001530 0.001185 0.001031 0.000771 2.404058 0.001063
2026-06-24 09:50:00,003 | synference | INFO | ============================================================
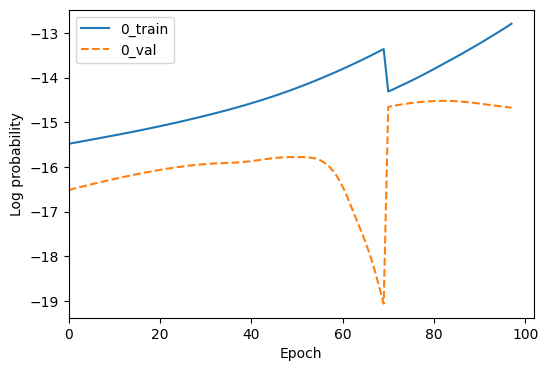
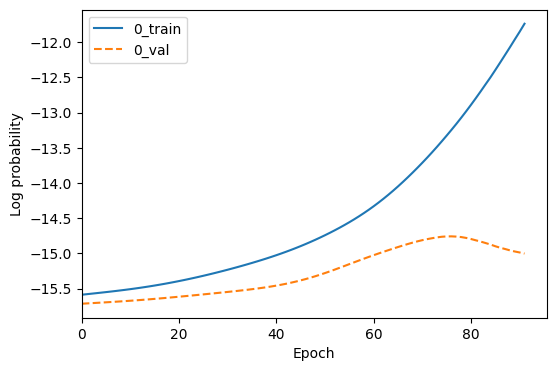
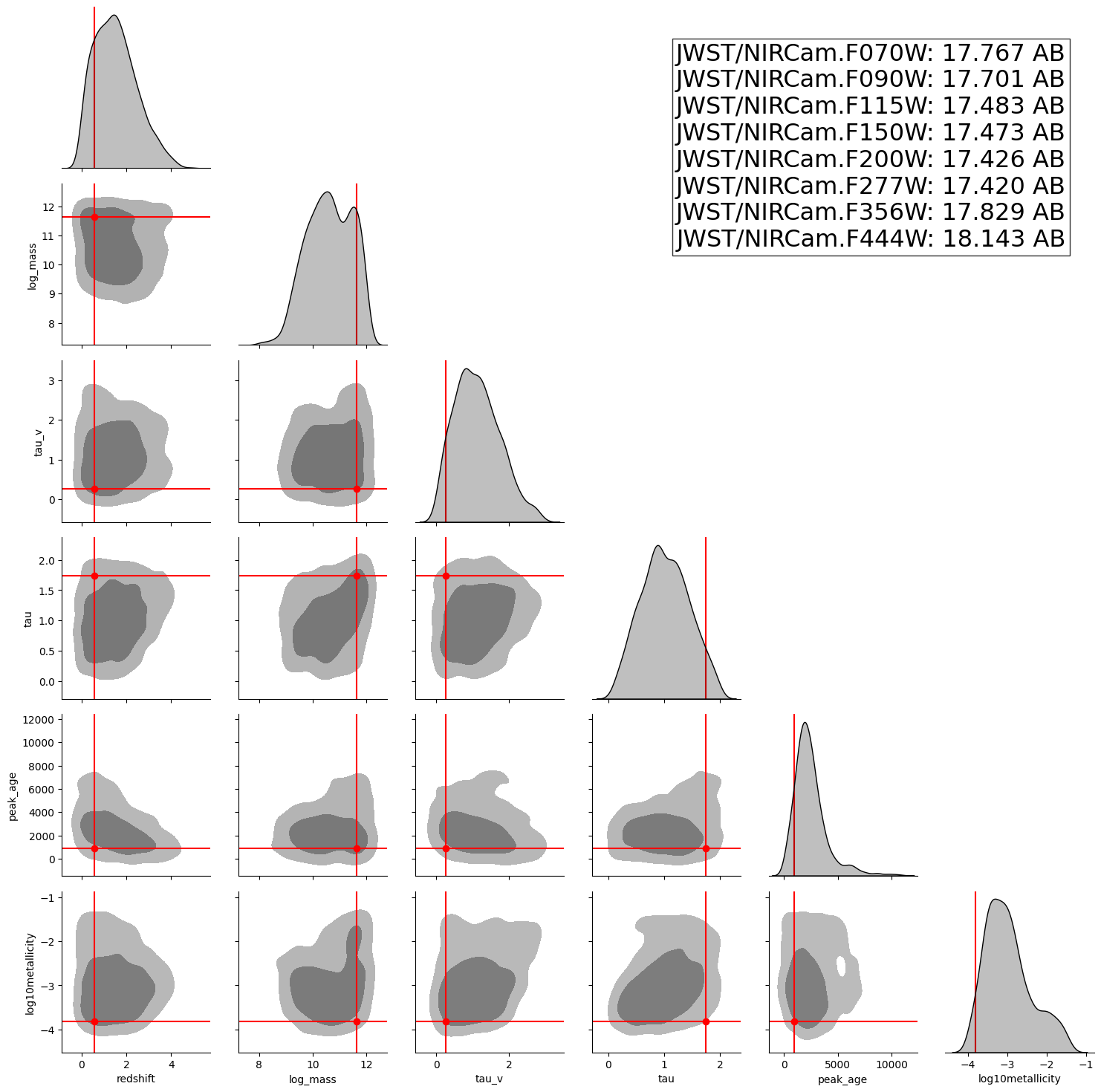

INFO:matplotlib.mathtext:Substituting symbol E from STIXNonUnicode
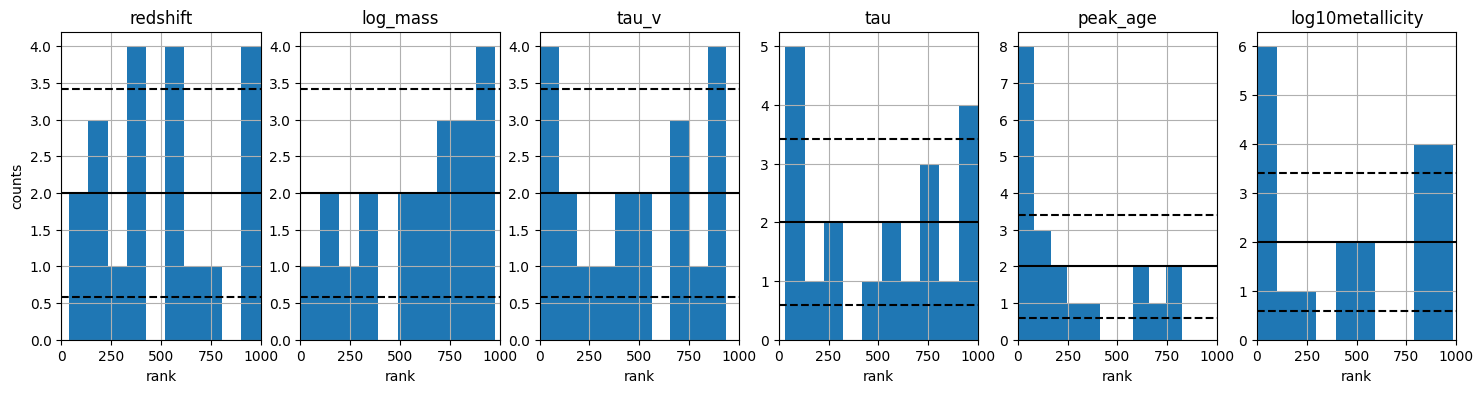
The first part of the output shows we split the training data into the training and testing splits, then we create the prior from the parameter library, and show the ranges of each parameter.
The next part shows us creating the neural density estimator (NDE) model, which is a mixture density network (MDN) with 4 components. The model is created using the sbi package, which is built on top of PyTorch.
Then the actual training happens - we see the training epochs increment until the model has stopped improving on the validation set. The training stops after 15 epochs with no improvement, as we set stop_after_epochs=15.
The model is pickled and saved to the output directory for this model, which is models/test_model/ by default. The summary of the training model is saved as a .json file in the same directory. And the configuration of the fitter is also pickled and saved to the same directory, which saves the feature and parameter configuration used for training. A model can be re-loaded later using the fitter.load_model_from_pkl method. We can save in a different format by changing the save_method
argument to e.g. torch or hickle.
Now we have a trained model. The validation metrics run which include:
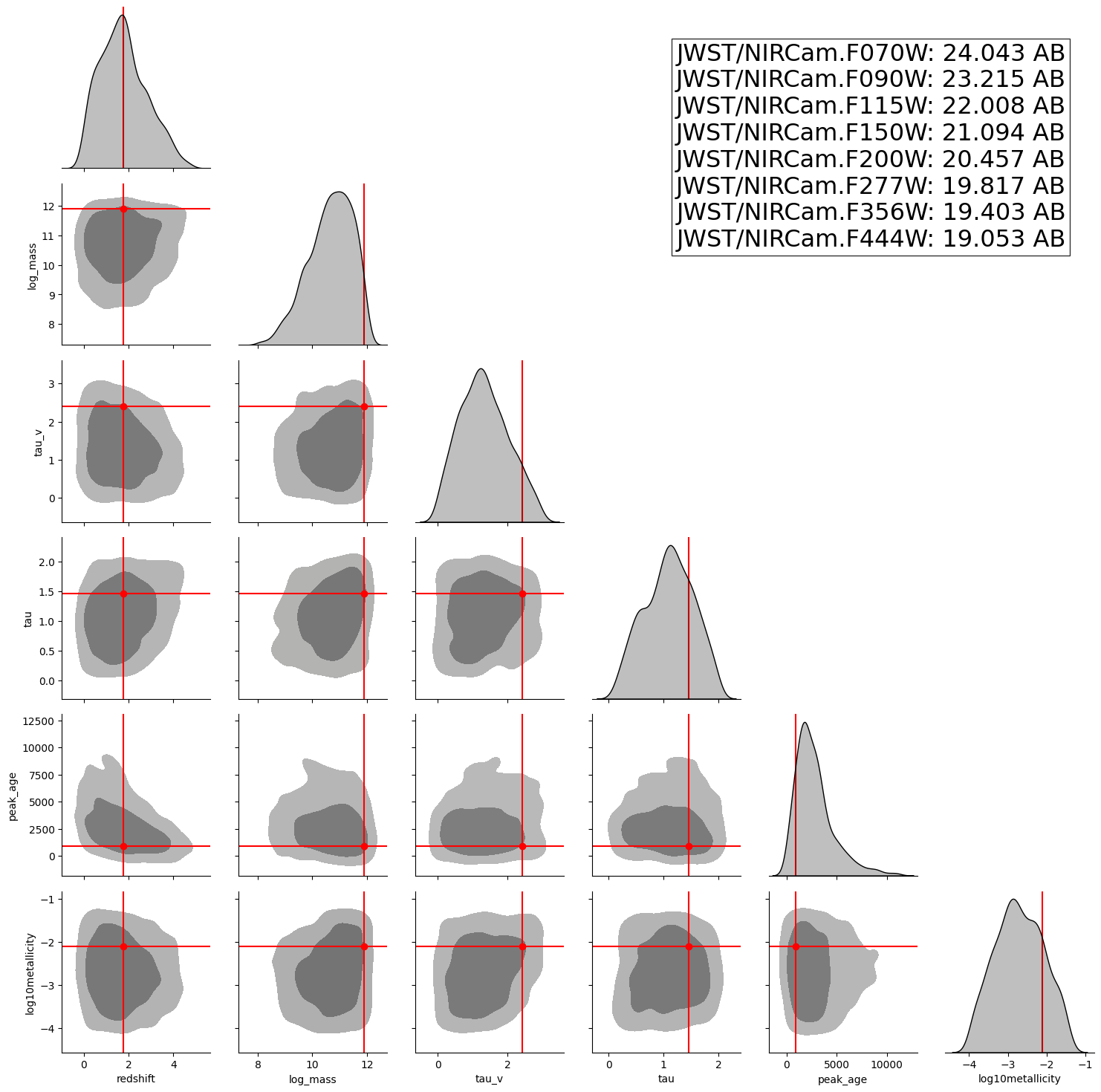
A posterior corner plot for a random observation from the test set.
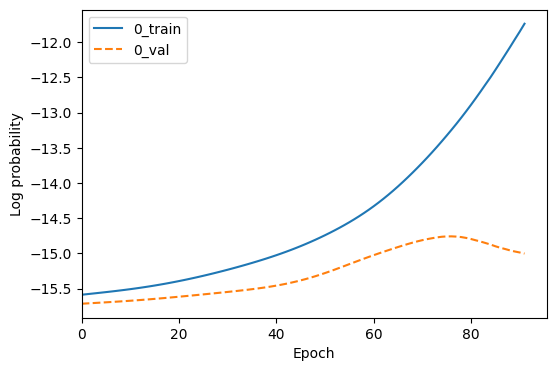
A loss plot which shows the training and validation loss over epochs.
A coverage plot which shows how well the credible intervals of the posterior match the true parameters.
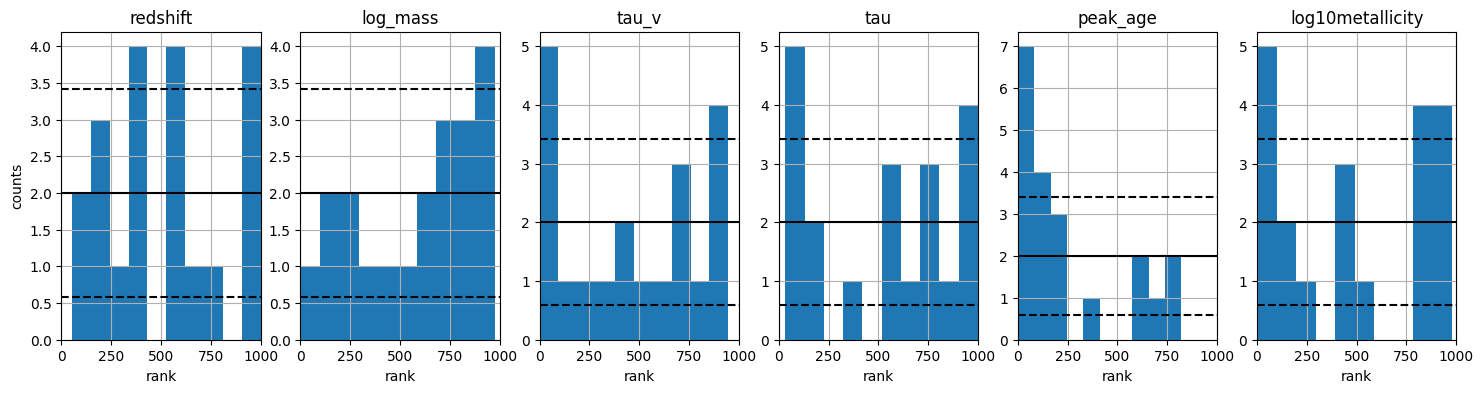
A ranks histogram which shows how well the posterior samples match the true parameters.
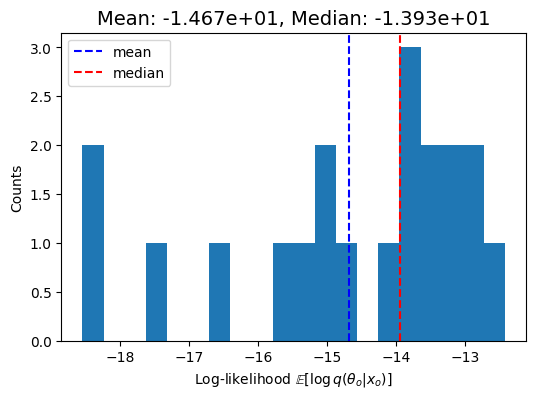
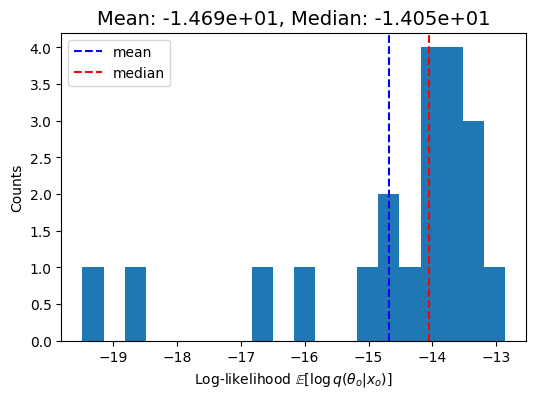
A log_probabiity plot which shows the log probability of the true parameters under the posterior.
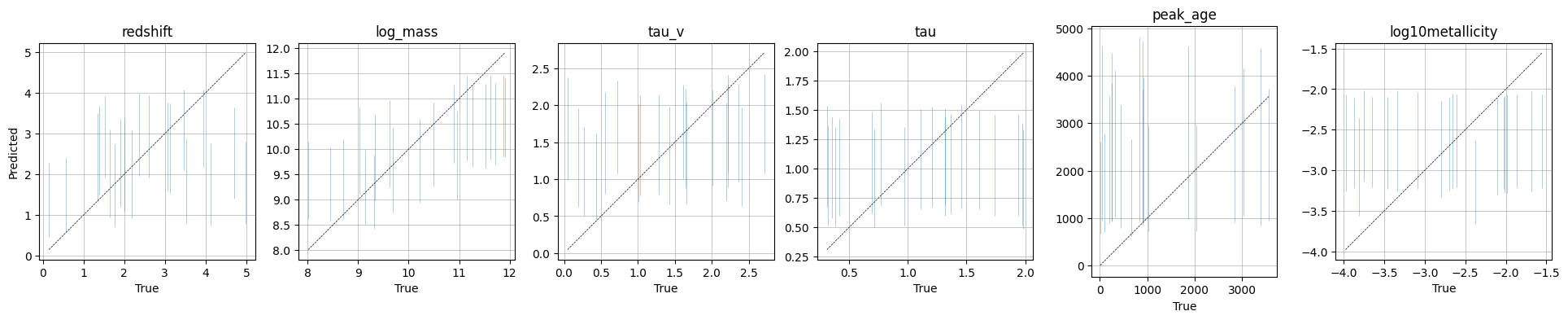
A True vs predicted plot which shows the true parameters vs the maximum a posteriori (MAP) estimate from the posterior.
These plots are shown in the output, and also saved to the plots/ directory in the output folder for this model.
Loading a Trained Model¶
We can load a trained model into an exisiting SBI_Fitter instance using the fitter.load_model_from_pkl method. This method takes the path to the pickled model file as an argument.
If only one model is present in the directory, we can simply provide the directory path and the method will find the model file automatically. If multiple models are present, we can provide the full path to the model file.
[12]:
fitter.load_model_from_pkl("test/test_test_1_posterior.pkl");
2026-06-24 09:50:03,151 | synference | INFO | Loaded model from /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/test_test_1_posterior.pkl.
2026-06-24 09:50:03,153 | synference | INFO | Device: cpu
Alternatively, we can create a new SBI_Fitter instance and load the model into that instance, using the class method load_saved_model. This method takes the path to the pickled model file as an argument, and returns a new SBI_Fitter instance with the model loaded.
[13]:
new_fitter = SBI_Fitter.load_saved_model("test/test_test_1_posterior.pkl")
2026-06-24 09:50:03,188 | synference | INFO | Loaded model from /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/test_test_1_posterior.pkl.
2026-06-24 09:50:03,189 | synference | INFO | Device: cpu
Plotting model loss¶
We can plot the model loss using the fitter.plot_loss method. This method will create a plot of the training and validation loss over epochs, and save it to the plots/ directory in the output folder for this model. By default, it will not overwrite existing plots, but you can change this with the overwrite argument.
[14]:
fitter.plot_loss(overwrite=True);
Plotting validation metrics¶
Whilst it does happen automatically during training, we can also plot the validation metrics of a trained model using the fitter.plot_diagnostics method. You can provide your own validation set, or by default it will use the test set from the last training run. By default, it will not create existing plots in the plots/ directory, but you can change this with the overwrite argument.
[15]:
fitter.plot_diagnostics();
2026-06-24 09:50:03,472 | synference | INFO | [ 4.11816883 11.87243652 1.001827 0.76882374 249.06600029
-1.98955381]
1246it [00:00, 284770.20it/s]
INFO:root:Saving single posterior plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/test_3_plot_single_posterior.jpg...
2026-06-24 09:50:13,448 | synference | INFO | shapes: X:(20, 8), y:(20, 6)
100%|██████████| 20/20 [00:00<00:00, 363.26it/s]
INFO:root:Saving posterior samples to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/posterior_samples.npy...
INFO:root:Saving coverage plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/plot_coverage.jpg...
INFO:root:Saving ranks histogram to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/ranks_histogram.jpg...
INFO:root:Mean logprob: -1.4380e+01Median logprob: -1.4078e+01
INFO:root:Saving true logprobs to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/true_logprobs.npy...
INFO:root:Saving true logprobs plot to /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/models/test/plots/plot_true_logprobs.jpg...
INFO:matplotlib.mathtext:Substituting symbol E from STIXNonUnicode
100%|██████████| 100/100 [00:00<00:00, 629.41it/s]

INFO:matplotlib.mathtext:Substituting symbol E from STIXNonUnicode
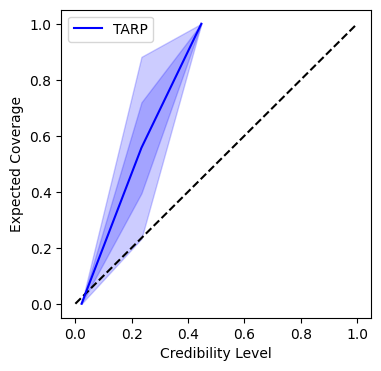
Getting model metrics¶
We can print and save metrics of the trained model using the fitter.evaluate_model method. This method will print the metrics to the console, and also save them to a .json file in the output directory for this model. The metrics include:
TARP (Tests of Accuracy with Random Points)
Log DPIT (Logarithmic Deviation of the Probability Integral Transform)
Mean Log Probability
Parameter-specific metrics (MSE, RMSE, Mean Absolute Error, Median Absolute Error, R-squared, Normalized RMSE)
[16]:
fitter.evaluate_model();
30s per sample.
Sampling from posterior: 100%|██████████| 20/20 [00:00<00:00, 278.09it/s]
100%|██████████| 200/200 [00:00<00:00, 621.01it/s]
Log prob: 100%|██████████| 20/20 [00:00<00:00, 71.72it/s]
2026-06-24 09:50:18,452 | synference | INFO | ============================================================
2026-06-24 09:50:18,454 | synference | INFO | MODEL PERFORMANCE METRICS
2026-06-24 09:50:18,454 | synference | INFO | ============================================================
2026-06-24 09:50:18,457 | synference | INFO | Full Model Metrics:
2026-06-24 09:50:18,458 | synference | INFO | ----------------------------------------
2026-06-24 09:50:18,459 | synference | INFO | TARP..................... 0.179750
2026-06-24 09:50:18,462 | synference | INFO | LOG DPIT MAX............. 0.544383
2026-06-24 09:50:18,463 | synference | INFO | MEAN LOG PROB............ -15.165296
2026-06-24 09:50:18,463 | synference | INFO | Parameter-Specific Metrics:
2026-06-24 09:50:18,464 | synference | INFO | ----------------------------------------
2026-06-24 09:50:18,465 | synference | INFO | Metric redshift log_mass tau_v tau peak_age log10metallicity
2026-06-24 09:50:18,466 | synference | INFO | --------------------------------------------------------------------------------------
2026-06-24 09:50:18,467 | synference | INFO | MSE 1.570325 0.805889 0.600973 0.334699 2900028.970240 0.619766
2026-06-24 09:50:18,468 | synference | INFO | RMSE 1.253126 0.897713 0.775225 0.578532 1702.947143 0.787252
2026-06-24 09:50:18,468 | synference | INFO | MEAN AE 0.987428 0.763321 0.653339 0.496383 1522.905631 0.678696
2026-06-24 09:50:18,469 | synference | INFO | MEDIAN AE 0.701837 0.703558 0.687861 0.524625 1597.350615 0.657969
2026-06-24 09:50:18,469 | synference | INFO | R SQUARED 0.999959 0.999977 0.999985 0.999991 -0.269930 0.999985
2026-06-24 09:50:18,470 | synference | INFO | RMSE NORM 0.001951 0.001397 0.001207 0.000901 2.650984 0.001226
2026-06-24 09:50:18,471 | synference | INFO | MEAN AE NORM 0.001537 0.001188 0.001017 0.000773 2.370713 0.001057
2026-06-24 09:50:18,471 | synference | INFO | ============================================================
Posterior Samples¶
We can sample the posterior for a given observation using the fitter.sample_posterior method. This method takes an observation, or a set of observations, as an argument, and returns samples from the posterior distribution. If no observation is provided, it will draw posterior samples for all observations in the test set.
[17]:
fitter.sample_posterior()
30s per sample.
Sampling from posterior: 100%|██████████| 20/20 [00:00<00:00, 280.45it/s]
[17]:
array([[[ 3.45166969e+00, 8.92087555e+00, 1.06789017e+00,
7.87134647e-01, 5.59775684e+03, -2.55248380e+00],
[ 3.51378369e+00, 9.63181686e+00, 2.15624094e+00,
1.14720249e+00, 3.70735205e+03, -3.08684754e+00],
[ 3.53048182e+00, 1.00553598e+01, 2.02119565e+00,
1.01249993e+00, 3.77516211e+03, -1.85435188e+00],
...,
[ 3.19240046e+00, 8.37380505e+00, 1.52905524e+00,
7.67466664e-01, 2.31099951e+03, -2.76483607e+00],
[ 2.39489079e+00, 8.85614777e+00, 1.68327332e+00,
1.16197062e+00, 5.29063281e+03, -2.62460351e+00],
[ 3.30668426e+00, 9.47163486e+00, 2.62036896e+00,
1.26219821e+00, 3.97689258e+03, -2.14080739e+00]],
[[ 3.14691329e+00, 9.53527260e+00, 1.09371006e+00,
5.23229599e-01, 4.37412207e+03, -2.57297564e+00],
[ 2.95255828e+00, 1.07640247e+01, 1.24583864e+00,
1.29674733e+00, 3.05762012e+03, -2.19051743e+00],
[ 3.35475850e+00, 8.69217587e+00, 5.45867920e-01,
2.54735351e-01, 1.23477380e+03, -1.93603456e+00],
...,
[ 1.85843670e+00, 8.24884224e+00, 2.45261812e+00,
1.01617169e+00, 8.30202148e+02, -3.90206790e+00],
[ 3.18018484e+00, 9.07877445e+00, 6.36879206e-02,
6.27801538e-01, 3.36912109e+03, -3.35505247e+00],
[ 1.63111997e+00, 1.02185879e+01, 1.33309543e+00,
1.05891776e+00, 2.93931421e+03, -3.61390829e+00]],
[[ 4.47980976e+00, 1.12535877e+01, 8.93392503e-01,
1.95172060e+00, 4.16850342e+03, -3.02587557e+00],
[ 2.95661116e+00, 9.72276211e+00, 7.83068359e-01,
1.07923102e+00, 2.73895386e+03, -2.54524326e+00],
[ 1.94508338e+00, 9.95222855e+00, 1.95247400e+00,
1.74444580e+00, 2.42424072e+03, -2.73124027e+00],
...,
[ 1.95377040e+00, 8.97600937e+00, 1.16788840e+00,
6.88634336e-01, 4.53067041e+03, -2.62739396e+00],
[ 1.91674304e+00, 9.41099930e+00, 1.09202576e+00,
1.18346655e+00, 1.83170105e+03, -2.91484380e+00],
[ 2.37379742e+00, 9.30647373e+00, 8.03316057e-01,
3.86088073e-01, 1.64376392e+03, -2.09855819e+00]],
...,
[[ 2.57203865e+00, 1.04231701e+01, 4.41537976e-01,
7.59894013e-01, 6.62154541e+02, -1.63450074e+00],
[ 3.25231147e+00, 9.14092731e+00, 8.20504189e-01,
5.57644725e-01, 1.89119421e+03, -2.26791239e+00],
[ 2.91910148e+00, 1.19883766e+01, 1.75425935e+00,
1.38262045e+00, 4.07427734e+03, -2.78745770e+00],
...,
[ 2.49924469e+00, 9.43959522e+00, 1.67610073e+00,
4.06102836e-01, 4.21045605e+03, -1.66902339e+00],
[ 2.75922561e+00, 9.43527412e+00, 1.51676404e+00,
1.57716012e+00, 2.46284619e+03, -2.05533600e+00],
[ 2.42595029e+00, 1.00328751e+01, 8.32322299e-01,
6.53183520e-01, 2.74075684e+03, -2.80372572e+00]],
[[ 1.70975685e-01, 1.13617783e+01, 1.41335464e+00,
1.25652933e+00, 2.77130859e+03, -3.45622993e+00],
[ 2.49391079e-01, 1.06991663e+01, 6.89491212e-01,
2.36222267e-01, 4.46802100e+03, -2.96580982e+00],
[ 1.52410102e+00, 1.10812721e+01, 1.22595906e-01,
1.24705899e+00, 3.77880078e+03, -3.10559821e+00],
...,
[ 1.23072910e+00, 8.91773129e+00, 1.77597296e+00,
1.04312289e+00, 8.86415820e+03, -2.54444695e+00],
[ 5.56661367e-01, 1.04572582e+01, 1.11337709e+00,
1.92930174e+00, 4.81166504e+03, -2.75972676e+00],
[ 1.46569252e+00, 1.19175854e+01, 1.61030197e+00,
1.30009055e+00, 3.43804492e+03, -1.88538623e+00]],
[[ 3.40551329e+00, 1.01751127e+01, 6.65958643e-01,
1.11142826e+00, 1.70375745e+03, -2.57837462e+00],
[ 3.31302166e-01, 1.02226486e+01, 2.06715918e+00,
1.26276755e+00, 4.40769824e+03, -1.82875061e+00],
[ 1.49553251e+00, 1.00184298e+01, 1.04892337e+00,
1.05079770e+00, 2.94873291e+03, -3.63706446e+00],
...,
[ 1.39738905e+00, 1.04983110e+01, 1.48622036e+00,
1.63662887e+00, 3.82353418e+03, -3.02690077e+00],
[ 2.42369437e+00, 9.16692257e+00, 1.37761927e+00,
1.06923711e+00, 3.79879883e+03, -2.46167994e+00],
[ 1.34584093e+00, 1.08439074e+01, 2.81629038e+00,
1.38642848e+00, 9.83055420e+02, -2.24916387e+00]]],
shape=(20, 1000, 6))
Next Steps¶
In the next tutorials, we will cover more advanced configurations for training SBI models, including different feature and parameter configurations, different NDEs, and different prior proposals. We will also cover how to use the trained models for inference on real data.